- Healthcare Provider Profiling
- Summary of Empirical Null for Profiling Healthcare Providers
Healthcare Provider Profiling
Summary of Empirical Null for Profiling Healthcare Providers
Abstract
Profiling of healthcare providers (such as dialysis facilities or physicians) is of nationwide importance. This analysis may lead to changes in budgeting allocations and even suspension. Existing profiling approaches assume the between-provider variation is entirely due to the quality of care (e.g. the risk adjustment is perfect), which is often invalid. As a result, these methods disproportionately identify larger providers, although they need not be “extreme.” To fairly assess healthcare providers, appropriate statistical methods are in urgent need to account for the unexplained variation due to imperfect risk adjustment. In response, we develop a novel individualized empirical null approach for profiling healthcare providersc to account for the unexplained between-provider variation due to the imperfect risk adjustment, which is robust to outlying providers. The proposed individualized empirical null approach is adaptable to different provider sizes, as the total variation used for assessing provider effects usually changes with the provider’s own sample size.
1 Introduction
Large-scale electronic health records derived from national disease registries have proven useful for measuring health care processes and outcomes. In order to monitor and quantify such differences, many patient level clinical outcomes are being closely monitored and summarized into provider-level measures, for example, in the Dialysis Facility Compare Program by Centers for Medicare & Medicaid Services (CMS). Provider profiling based on these clinical outcomes can help patients make more informed decisions as to their choice of providers, and also aid overseers and payers in identifying providers whose outcomes are worse or better than a normative standard, in order to signal the need for further reviews or to target quality improvement programs. The statistical analysis along with further reviews may lead to changes in budgeting allocations and even suspension for those providers with extremely poor outcomes. Thus, accurate profiling of healthcare providers with extreme performance is of nationwide importance (XX). Given the high stakes of such evaluations, it is crucial that the statistical methods for provider profiling appropriately account for differences in patient characteristics and suitably allow for unexplained variation due to imperfect risk-adjustment.
Our endeavor is motivated by the study of end-stage renal disease (ESRD). End-stage renal disease (ESRD) is one of the most deadly and costly diseases. In 2016 there were 726,331 prevalent cases of ESRD in the United States (?), which represents an increase of 80 since 2000. Between 2015 and 2016, Medicare fee-for-service (FFS) spending for beneficiaries with ESRD rose by 4.6 (Figure 1b), from billion to billion, accounting for 7.2 of overall Medicare paid claims. These high health care expenditures represent a major health care burden and are worthy of special scrutiny. In order to identify extreme (poor or excellent) performance and to intervene as necessary, outcomes of patients associated with dialysis facilities or physicians are routinely monitored most often by both government and private payers. This monitoring can help patients make more informed decisions, and can also aid consumers, stakeholders, and payers in identifying facilities where improvement may be needed, and even closing or ending those with extremely poor outcomes. For such purposes, both fixed effects (FE) and random effects (RE) approaches have been widely used. However, existing FE and RE approaches assume the between-provider variation is entirely due to the quality of care, which is often invalid; e.g. unobserved socioeconomic factors and comorbidities may differ substantially across providers and contribute to the between-provider variation. As a result, the usual standard normal distribution assumption for the null distribution of the test statistics is invalid, leading to large differences in subsequent profiling. In particular, the FE method disproportionately profiles larger providers, although their difference from the national average may not be clinically meaningful and such providers need not be “extreme.”
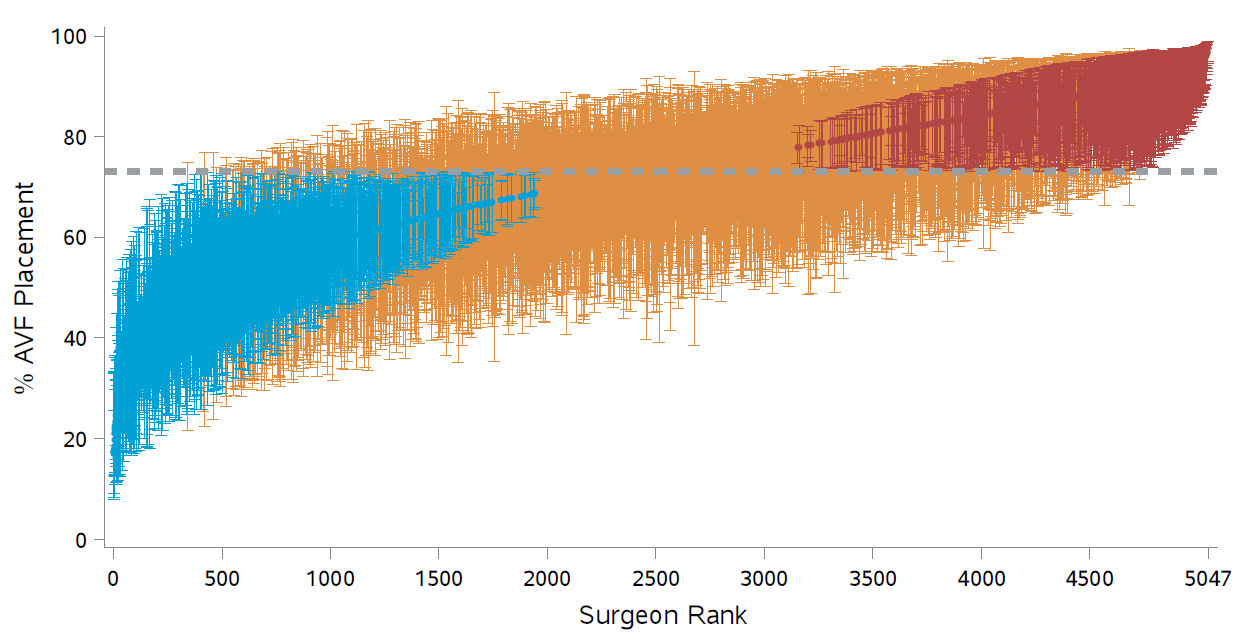
Figure 1: RE-based adjusted percentages and 95 confidence intervals; Dashed line: median value; Blue: significantly below; Red: significantly above.
The idea of empirical null was introduced in Efron (2004) in the context of multiple testing with a uniform null distribution. Kalbfleisch and Wolfe (2013) propose using the empirical null distribution of the FE-based Z-scores to assess outlying providers. Specifically, a robust estimation technique is applied to obtain the mean and variance estimates of the FE-based Z-scores, which can then be used as reference in hypothesis testing. However, in application with provider profiling, the total variation for assessing provider effects and the distribution of the test statistics usually change with the provider’s sample size. This leads to individualized null distributions for the test-statistics, precluding the application of existing empirical null approaches. To fairly assess providers, we propose an individualized empirical null approach, which is adaptable to different provider sizes and are robust to outlying providers. Linear models 3 are presented first to introduce the proposed framework, and our proposed method accommodates many other types of outcomes, such as hospital admissions and ED visits in a Poisson model and readmission in a logistic model. Our contribution to the literature can be summarized as follows: First, in recognition of the fact that risk-adjustment is never perfect, the proposed individualized empirical null approach accounts for the unexplained variation between providers. Second, the method is adaptable to different provider sizes and avoids the bias against large providers. Finally, the method incorporates the contamination of outliers, and is robust for identifying outlying providers.
2 Individualized Empirical Null for Linear Models
Let represent a continuous outcome for subject in provider , , where is the sample size for provider . Consider an underlying linear regression model
where is the provider effect, is the random noise, is a vector of patient characteristics, and the regression coefficient, , measure the within-provider relationship between the covariates and the response. Here is a random effect, which can be thought of as an unobserved confounders.
We note that, in profiling applications with national disease registries, the number of patients is large so that , and can be precisely estimated. To simplify the notation, we proceed below as though their values are known. Let be the risk adjusted response, so that the model becomes
2.1 FE and RE Approaches
The FE-based Z-score for a sharp null hypothesis is , where . Assuming that large values of correspond to poor outcomes, the th provider is flagged as worse than expected if , where is the upper th quantile of the standard normal distribution. However, in practice, the empirical distribution of z-scores is more dispersed than the standard normal distribution (Figure 1a), a phenomenon known as over-dispersion. As illustrated in Figures 1b-1d, the variation of Z-scores is larger for providers with larger size. In fact, when the randomness of provider effects is taken into account, the marginal variance of the Z-scores is , which is a linear function of the sample size . The issue is that the FE approach assumes that the risk-adjustment is perfect, which, however, is often violated in practice. As a results, the usual standard normal distribution assumption for the null distribution is invalid, leading to large differences in subsequent profiling. In particular, the FE method disproportionately profiles larger providers, although their difference from the national average may not be clinically meaningful and such providers need not be “extreme.”
Alternatively, the RE approach is based on the best linear unbiased predictor (BLUP) arising from the “posterior” distribution of given the data. The corresponding Z-score is given by , where plays the role of a shrinkage factor. The RE approach gives estimates with a smaller mean squared error than the FE estimate, which, however, is achieved at the cost of bias. The bias is especially substantial for providers with small sizes. Moreover, the RE-based Z-score suffers from the same problem as the FE approach and disproportionately profiles large providers. As illustrated in Figure 2, if a provider treats a sufficiently large number of patients, even a slight departure from the national norm is likely to be profiled as extreme. It should also be noted that the naive use of RE can lead to biased estimation of provider effects and regression coefficients when covariates are correlated with the provider effects.
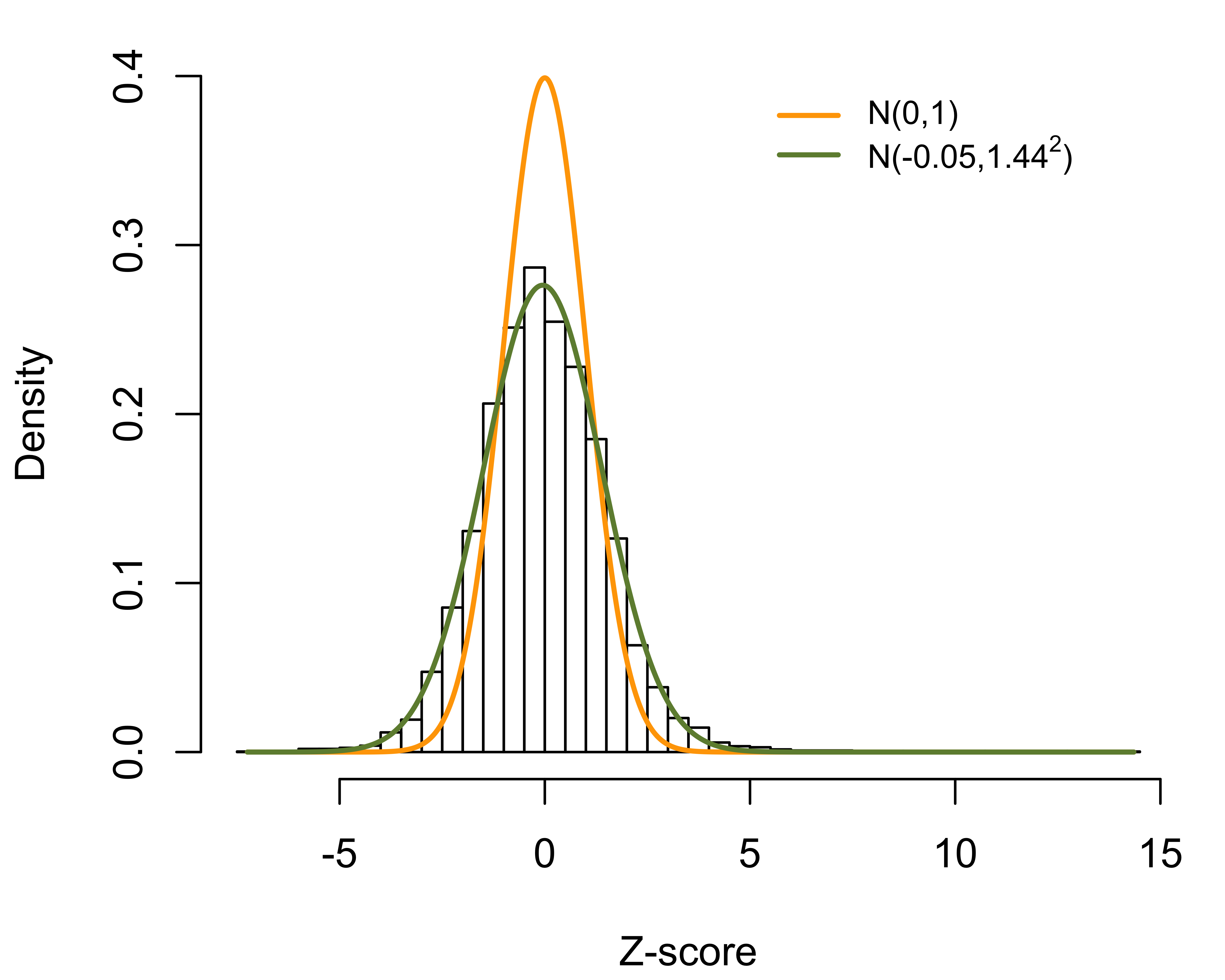 | 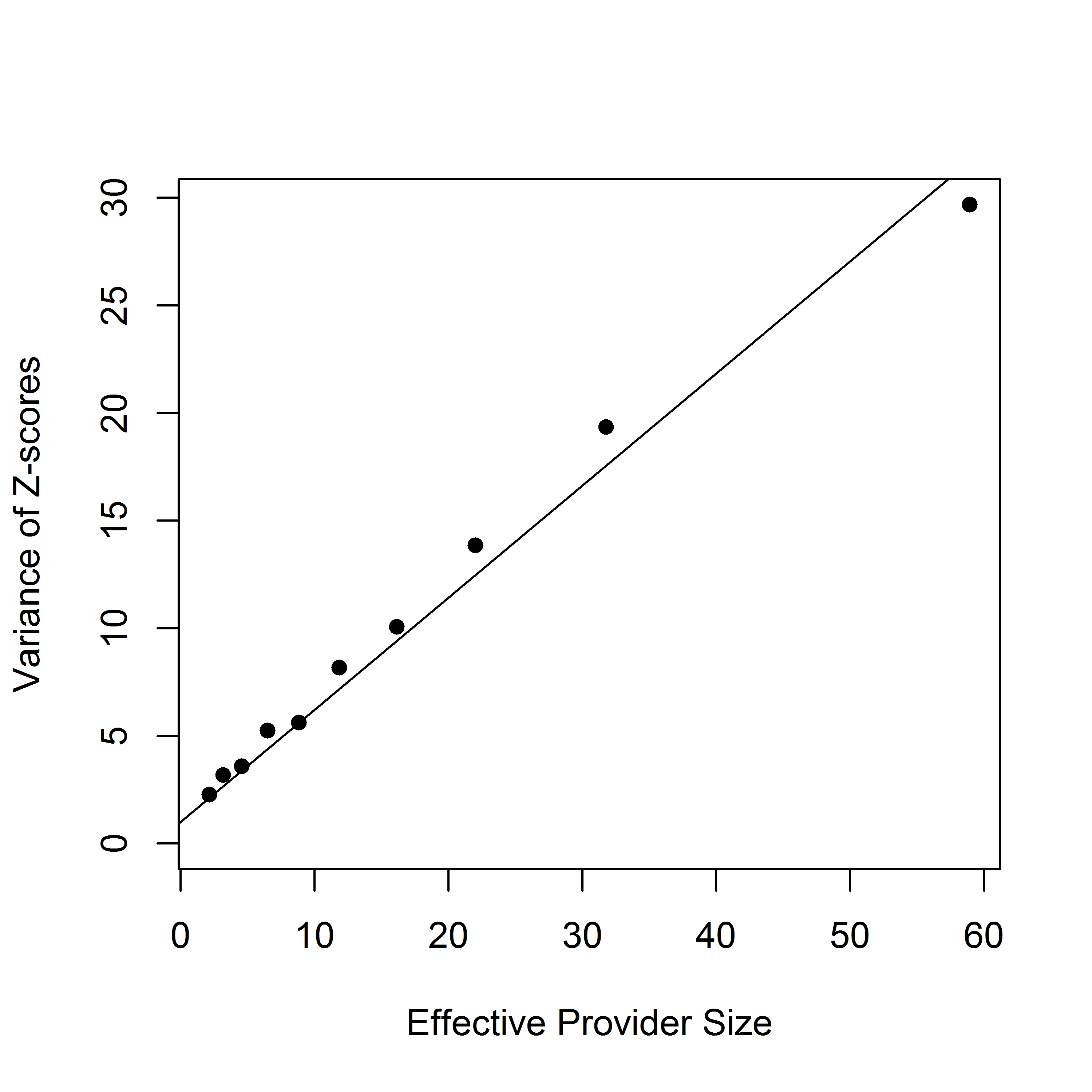 | 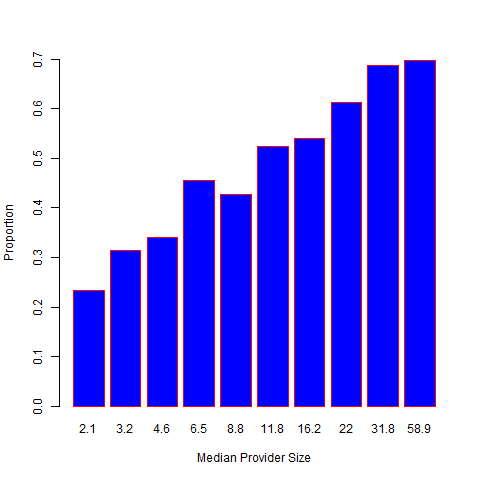 |
Figure 2: Histogram of FE-based Z-scores for 6,363 dialysis facilities; overall and stratified by provider sizes..
2.2 Individualized Empirical Null
In practice, risk-adjustment is never perfect. Moreover, the existence of outlying providers will result in an over-estimation of the between-provider variation. The corresponding power is affected; likely to falsely forgive extreme outliers. To incorporate imperfect risk-adjustment and remove the effects of outlying providers, we consider an individualized two-group model. To illustrate the proposed method, we utilize the FE-based Z-scores, although the RE-based Z-scores can be applied as well. Suppose that is either from a null distribution with a prior probability or from a distribution of outliers with probability . Assume the corresponding mixture density is given by a two-group model,
where the null density is from a normal distribution with mean and variance , and is a density for outliers. Here . To obtain robust estimates of and , we assume that the non-null density for the th provider has support outside an interval
where are initial estimates, and is a specified number (e.g. 1.64). Let , , the cardinality of , , and is the normal density with mean and variance . Let , where is the cumulative distribution function of , be the probability that a null Z-score with sample size falls in the interval . The likelihood is written as
One can numerically solve the optimization problem and find the maximum likelihood estimates, denoted as , and , respectively. The th provider is flagged as worse than expected if , where
Note that a robust M-estimation for heteroskedastic regression can be used to obtain the initial estimates of . This M-estimation is simple, but can give biased estimates of the variance, which motivated the proposed approach.
2.3 Frequentist Interpretation
Consider the provider-level sample mean . Unconditionally on , denote the marginal mean of by . If provider comes from the null distribution, is an unbiased estimator of the population mean; i.e. . Otherwise, . Thus, can be considered as a test statistics for a null hypothesis against the alternative hypothesis . The corresponding p-value is given by
2.4 Bayesian Interpretation
Under the linear model (2), the predictive distribution of is given by . The predictive p-value for identifying extreme providers with mean larger than plausible
which leads to the same p-value as the frequentist interpretation.
2.5 Remarks
A simple approach (termed naive approach) is to directly estimate from a random effects model and standardize the Z-scores based on their marginal variance, so that the standardized Z-scores follow the standard normal distribution. However, the existence of outlying providers will result in an over-estimation of , which will affect the power to identify extreme outliers. The idea of the empirical null was introduced in Efron in the context of multiple testing with a uniform null distribution. Kalbfleisch and Wolfe proposed using the empirical null distribution of the FE-based Z-scores to assess outlying providers. Specifically, a robust estimation technique is applied to obtain the mean and variance estimates of the FE-based Z-scores, which can then be used as reference in hypothesis testing. However, in application with provider profiling, the total variation for assessing provider effects and the distribution of the test statistics usually change with the provider’s sample size. This leads to individualized null distributions for the test-statistics, precluding the application of existing empirical null approaches. These concerns motivate the proposed individualized empirical null procedure.
3 Extensions to Non-Linear Models
3.1 Generalized Linear Models
The proposed approach accommodates many other types of outcomes.
Consider a generalized linear model
where is the conditional density function, is a dispersion parameter, is a known function. Here is a specific known function with and . Here primes denote differentiation with respect to . We assume , where and are estimated with great precision, which is justified given the large sample size for most profiling applications. The FE-based Z-score for a sharp null hypotheses can be constructed via a score test statistic
where . To incorporate unexplained variation between providers, we assume . Applying a first-order Taylor expansion of and around , the marginal variance of can be approximated as
which is a linear function of .
Example outcomes:
-
Continuous outcome: under the linear model (2), we have and .
-
Binary Outcomes: let denote a binary outcome (e.g. hospital readmission within 30 days of index discharges). Consider a logistic model , where . Here , and .
Assuming , the marginal variance of can be approximated as , where . The proposed individualized empirical null approach can be easily applied based on .
-
Poisson outcomes: let be a Poisson outcome (e.g. ED visits) for the th patient in the th provider. Consider a Poisson model , with and . Assuming , the approximate marginal variance of is given by , where .
3.2 Discrete Survival Models
In large-scale disease registries, ties in event times can be extremely numerous. Various approximation procedures, have been proposed for the partial likelihood to account for ties among failure times. However, when the ties are extremely numerous these approximation procedures can be seriously inadequate. As the proportion of ties expands, the bias of these approximations and the computational burden increase quickly, preventing the use of the standard partial likelihood approach. When the sample size is substantial and there is only a modest number of distinct event times, it becomes feasible to treat the baseline hazard at each event time as a parameter in the estimation algorithm, which also facilitates obtaining the absolute hazard. Moreover, in large-scale datasets, the number of unique failure times can be much smaller than the sample size. For example, in the national dialysis database, the time to event is rounded to the nearest days; thus, for 30 day readmission there would be numerous ties and only 30 discrete event times. This motivates the use of a discrete-time model.
Let be the unique event times. Let denote the set of labels associated with individuals failing at time . Let be the set of labels associated with individuals censored in time period . Let denote the at risk set at time . Let be a -dimensional covariate vector for subject . Assume a general model, where the hazard at time for the -th patient with covariate is denoted by . The likelihood function is given by
and the corresponding log-likelihood function is then given by
where is the at-risk indicator and is the event indicator at . Consider the formulation
where is a monotone and twice-differentiable function. The log-likelihood function of and can be written
While other transformations are possible we will assume a log link that gives a discrete relative risk model, for which,
In what follows, we consider two commonly used logit and log links, which correspond to the discrete logistic and the discrete relative risk models, respectively.
Consider the discrete logistic link function:
where is the baseline hazard at time . where is the baseline hazard at time . The corresponding log-likelihood function is given by , which is additive, without the inner sum over the risk set, and hence is more conducive to utilize stochastic approximations. This model also facilitates obtaining the absolute hazards. Here
The log-likelihood function is
Alternatively, consider the log link The log-likelihood function is
Using B-splines, the log-likelihood function is
where is the at-risk indicator at , is the event indicator at , , and are the same as those defined in Aim 1a. The need is then to maximize this likelihood over both and .
The FE-based Z-score for a sharp null hypotheses can be constructed via a score test statistics
where . Note that in most profiling applications, and are estimated with great precision, which is justified given the large sample size in the large-scale disease registries (e.g. an example is shown in Figure 11 with 541,769 discharges from 6,937 dialysis facilities). To incorporate unexplained variation between providers, we assume that follows a random distribution with mean 0 and variance . Applying a first-order Taylor expansion, the marginal variance of can be approximated as
4 Simulation
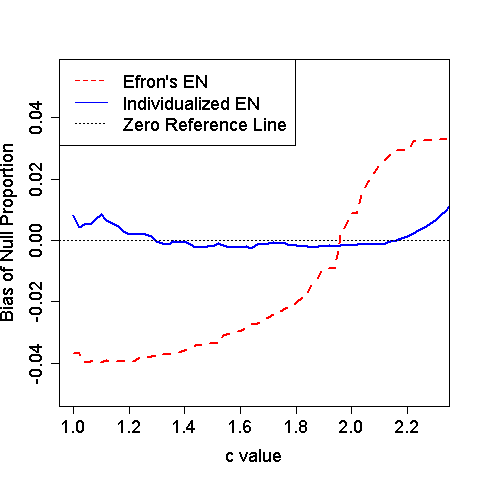
Figure 3: Estimated bias for null proportion with various values of .
Binary outcomes were generated from a logistic regression with 600 providers and 10% of them being outlier. The null provider effect was simulated from a standard normal distribution. The outlying provider effects were fixed at 3 times . We varied the sample size such that one third of providers had 75, 150 and 300 patients, respectively. The tuning parameter in the truncated interval took values in by an increment of 0.02. Figure XX compares the bias of the estimated null proportion for various values of . The proposed individualized empirical null provides sounds estimation. In contrast, the original empirical null ignores the fact that the test statistics for provider profiling changes with the provider’s sample size, and hence, leads to biased estimations of the null distribution and the proportion of null effects; when is small, the is under-estimated and the power to identify extreme providers will be reduced. When is large, the is over-estimated and the Type I error will be inflated.