Our projects & software
From High Dimensional Data to Healthcare Provider Profiling
Develop statistical methods and computational algorithms which include high dimensonal variable selection, survival analysis, statistical optimization and causal inference. Develop methods to measure the performance of health care providers by supplying interested parties with information on the outcomes of health care.
Healthcare Provider Profiling
Develop methods to measure the performance of health care providers by supplying interested parties with information on the outcomes of health care.
Competing Risks
Analysis of Readmissions Data Taking Account of Competing Risks.
Learn more, Competing RisksHealthcare provider profiling is of nationwide importance. To improve quality of care and reduce costs for patients, the Centers for Medicare and Medicaid Services (CMS) monitors Medicare-certified healthcare providers (e.g. dialysis facilities, transplant centers and surgeons) nationwide with various quality measures of patient outcomes (e.g. readmission, mortality and hospitalization). This monitoring can help patients make more informed decisions, and can also aid stakeholders and payers in identifying providers where improvement may be needed, and even fining or closing those with extremely poor outcomes. Therefore, it is important that the quality measures for profiling providers be accurate.
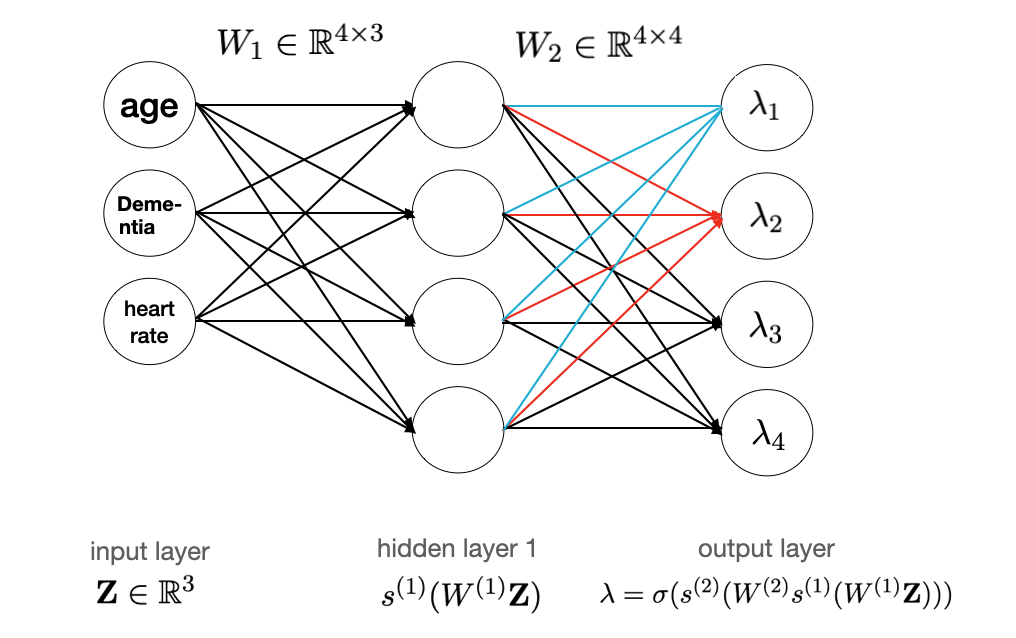
Fixed Effects
"FEprovideR: Fixed Effects Logistic Model with High-Dimensional Parameters.
Learn more, Fixed EffectsA stuctured profile likelihood algorithm for the logistic fixed effects model and an approximate expectation maximization (EM) algorithm for the logistic mixed effects model.

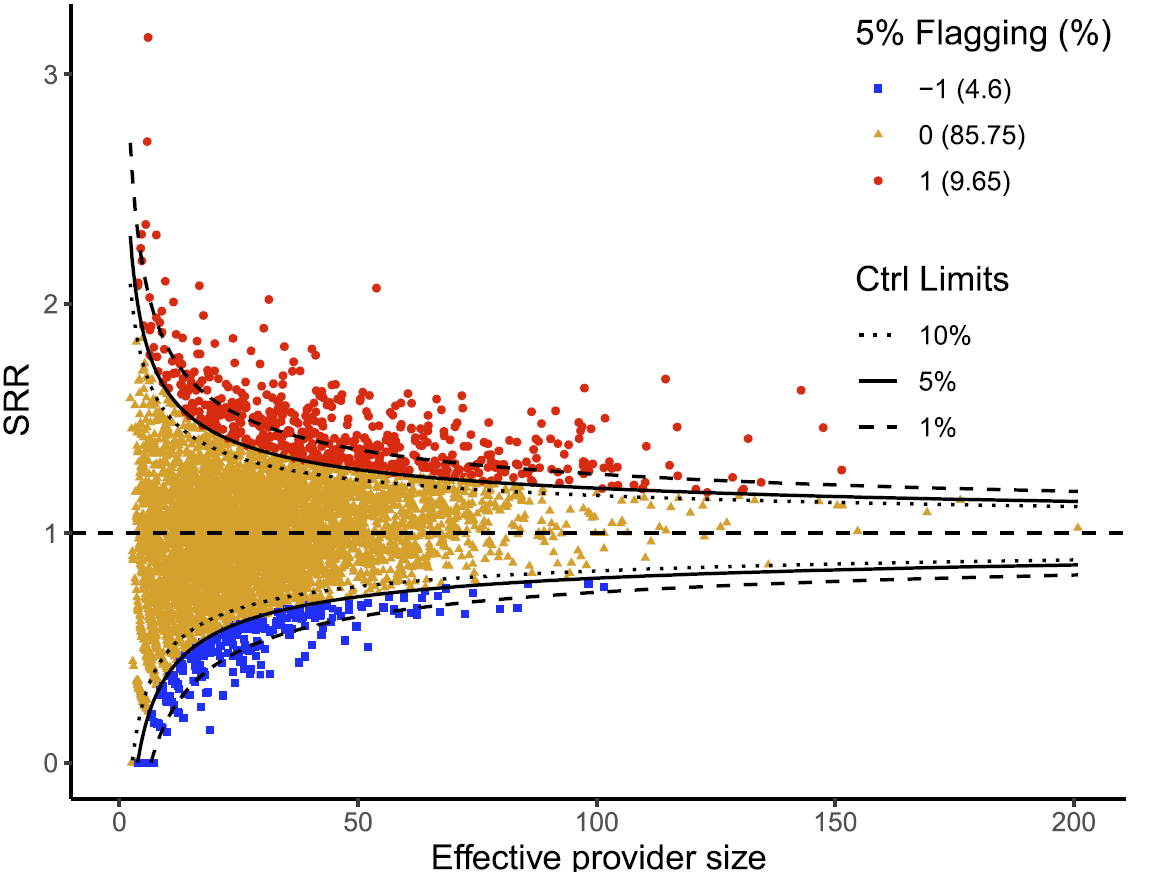
Funnel Plot
ppfunnel creates elegant funnel plots for profiling health care providers.
Learn more, Funnel PlotThe ppfunnel R package offers a comprehensive solution for creating sophisticated funnel plots, essential for profiling healthcare providers and assessing bias. This tool supports both individual-level data (e.g., patient or hospital discharge data) and aggregated provider-level data (e.g., hospital or facility summaries), providing flexibility to users to input data in the format that best suits their study requirements. ppfunnel effectively handles multiple outcome types, including Poisson count outcomes and Bernoulli binary outcomes. Users can customize their analysis by choosing between different indicators of interest, such as indirectly standardized ratios (ISR) and proportions. The package incorporates a range of advanced statistical methods, including fixed effects modeling, various overdispersion adjustments, and empirical null models, ensuring robust and accurate funnel plots, especially in the presence of incomplete risk adjustment. Additionally, ppfunnel offers extensive options for setting control limits and flagging providers, enabling users to apply various statistical tests and thresholds to effectively identify and highlight performance variations among providers.
Variable selection
ppLasso: powerful solution for efficient variable selection in multi-center data.
Learn more, Variable selectionIn the contemporary era of big data, the volume of health data generated by healthcare providers, such as hospitals and dialysis facilities, has experienced a remarkable upsurge. As a result, traditional statistical tools for variable selection in high-dimensional data have encountered challenges in maintaining computational efficiency. In response to this issue, the ppLasso R package has been meticulously developed, offering a powerful solution for efficient variable selection in multi-center data. Demonstrating its superiority, our statistical tool outperforms existing methods by a substantial margin, as validated through both simulated studies and real-world data.
Statistical Methods and Computational Algorithms for Big Data Analysis
Develop statistical methods and computational algorithms which include high dimensonal variable selection, survival analysis, statistical optimization and causal inference.
Time Varing Effects
Block-Wise Steepest Ascent for Large-Scale Survival Analysis with Time-Varying Effects.
Learn more, Time Varing EffectsThe time-varying effects model is a flexible and powerful tool for modeling the dynamic changes of covariate effects. However, in survival analysis, its computational burden increases quickly as the number of sample sizes or predictors grows. Traditional methods that perform well for moderate sample sizes and low-dimensional data do not scale to massive data. We propose a block-wise steepest ascent procedure by leveraging the block structure of parameters inherent from the basis expansions for each coefficient function. The algorithm iteratively updates the optimal block-wise search direction, along which the increment of the partial likelihood is maximized. The proposed method can be interpreted from the perspective of the Minorization-Maximization algorithm and increases the partial likelihood until convergence.
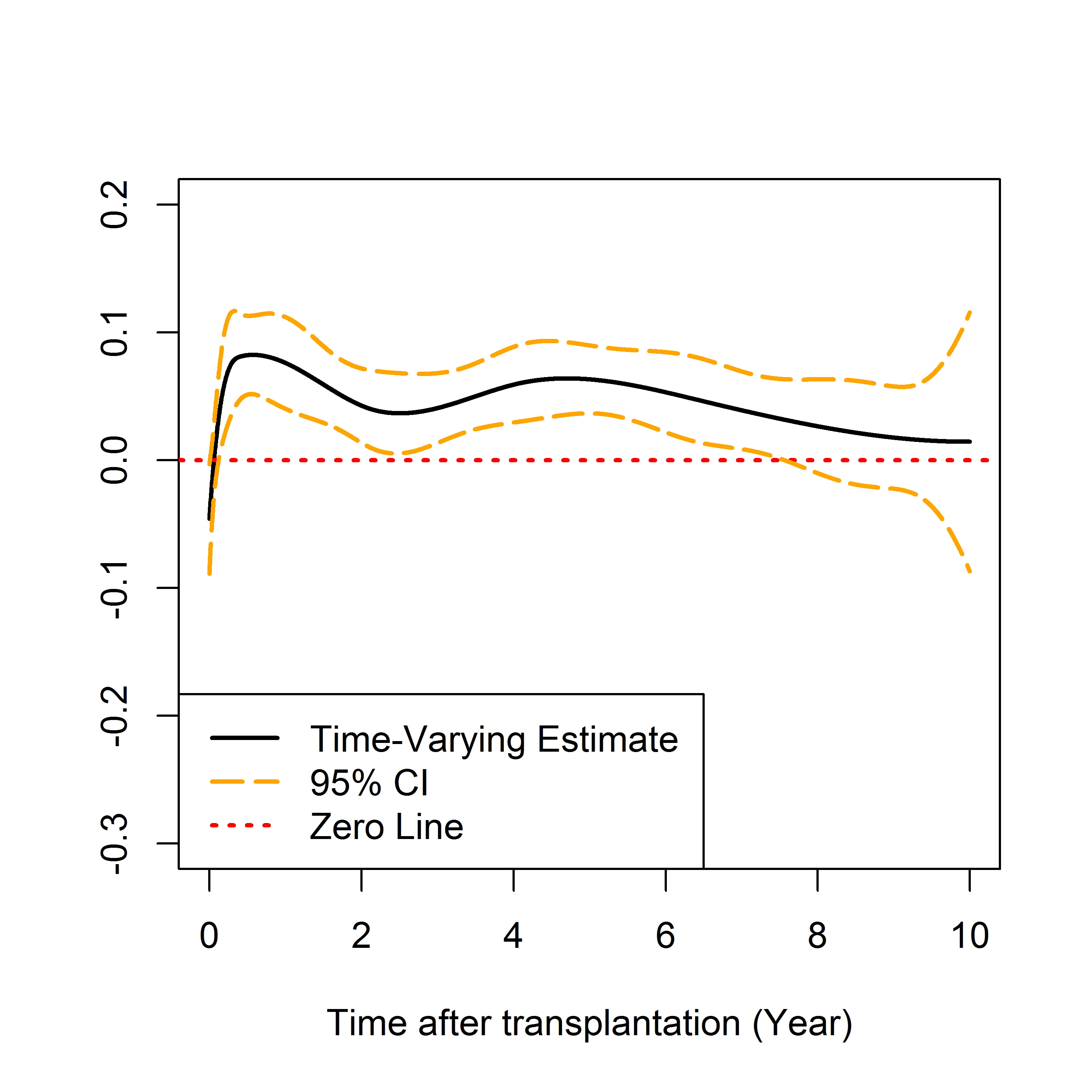
Scalable Proximal
Scalable Proximal Methods for Cause-Specific Hazard Modeling with Time-Varying Coefficients.
Learn more, Scalable ProximalSurvival modeling with time-varying coefficients has proven useful in analyzing time-to-event data with one or more distinct failure types. Existing methods suffer from numerical instability due to ill-conditioned second-order information. The estimation accuracy deteriorates further with multiple competing risks. To address these issues, we propose a proximal Newton algorithm with a shared-memory parallelization scheme and tests of significance and nonproportionality for the time-varying effects. A simulation study shows that our scalable approach reduces the time and memory costs by orders of magnitude and enjoys improved estimation accuracy compared with alternative approaches.
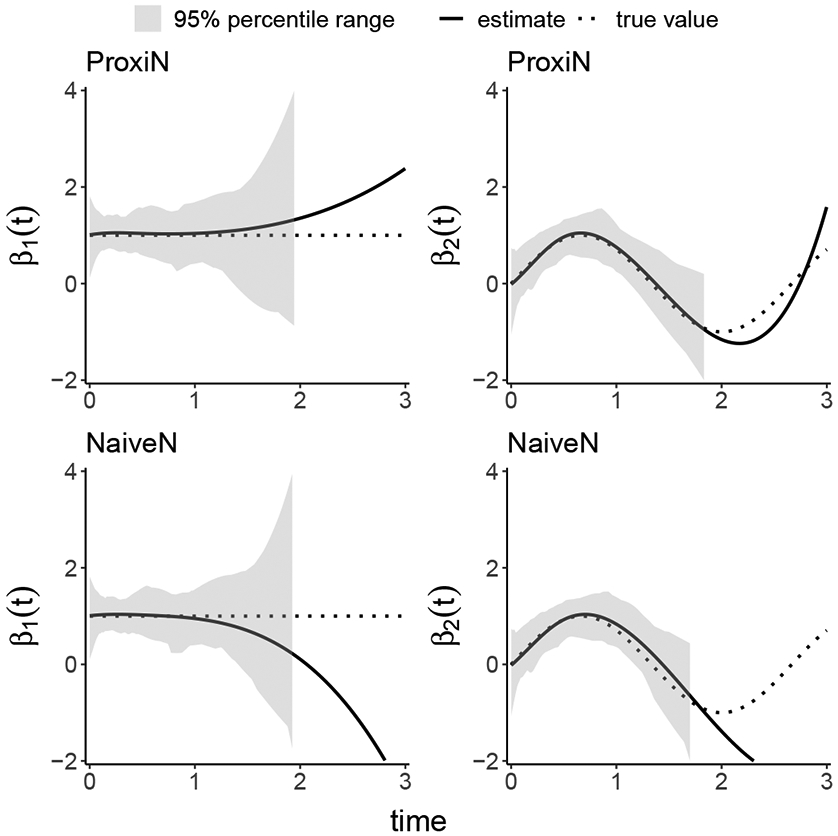
Deep Learning
Python package DeepLearningKL: survival analysis with deep learning.
Learn more, Deep LearningThis project is to train a deep learning model in Survival Analysis. However, we allow user to incorporate prior information, which can be either statistical models or other neural networks. KL divergence is used for incorporating, which measures the difference between prior information and local information. The weights of prior and local information are selected by hyperparameter tuning and higher weights of prior model mean the model tends to believe more prior information than the local information, which means the quality local data may not be so satisfactory. Besides, we also do an extension from single-risk to competing risk case, which means our software can also handle competing risk data.
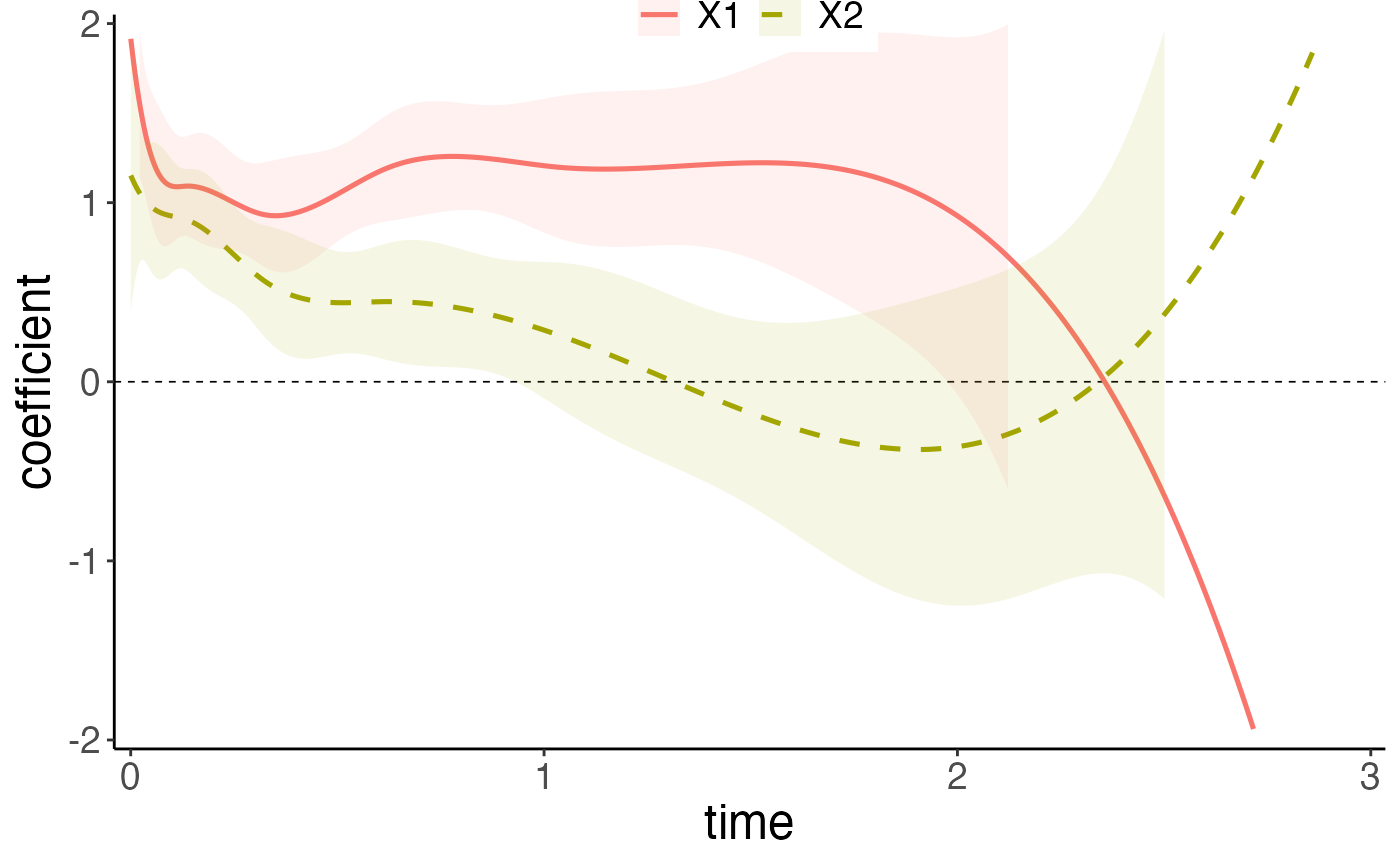
time-varying
Cox non-proportional hazards models with time-varying coefficients.
Learn more, time-varyingsurtvep is an R package for fitting Cox non-proportional hazards models with time-varying coefficients. Both unpenalized procedures (Newton and proximal Newton) and penalized procedures (P-splines and smoothing splines) are included using B-spline basis functions for estimating time-varying coefficients. For penalized procedures, cross validations, mAIC, TIC or GIC are implemented to select tuning parameters. Utilities for carrying out post-estimation visualization, summarization, point-wise confidence interval and hypothesis testing are also provided.
Missing Data
MISSVS: Multiple imputation and variable selection for missing data
Learn more, Missing DataThe MISSVS package provides powerful tools for multiple imputation and variable selection in the presence of missing data. Ideal for researchers dealing with incomplete datasets, this package offers a comprehensive solution to handle missingness and ensure robust statistical inference.
Discrete Failure Time Models
DiscreteKL: Kullback-Leibler-Based Discrete Failure Time Models
Learn more, Discrete Failure Time ModelsPrediction models built based on a single data source may suffer from rare event rates, small sample sizes, and low signal-to-noise ratios. Incorporating published prediction models from large-scale studies is expected to improve the performance of prognosis prediction. Thus, we propose Kullback-Leibler-based (KL) discrete failure time models to integrate published prediction models (external models) with an individual-level time-to-event dataset (internal data) while accounting potential heterogeneity among different information sources.